Create and Upload a Dataset
Create a new Dataset¶
A Dataset is a collection of data. If you have used Github, datasets in FloydHub are a lot like code repositories, except they are for storing and versioning data.
To create a new Dataset, visit www.floydhub.com/datasets and click on the "New Dataset" button on the top right hand corner.
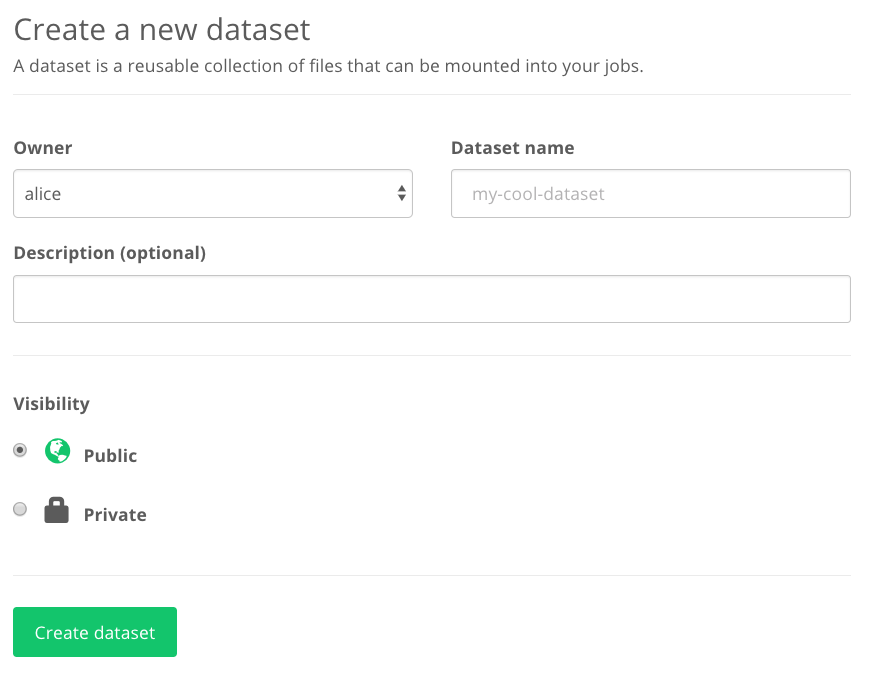
Give the dataset a name and a description.
The Owner field defines the user namespace to which this dataset belongs. If you are part of a Team select the name of your Team.
The Visibility field indicates who can see your dataset. If you set it to
Public, anyone can see your dataset and data versions. If you are working on
an open source project, this is a great way to share and contribute to the
FloydHub community. If your data is proprietary, please select Private. This
will ensure that only you and your team will have access to this dataset.
The section below shows how to upload a dataset from your local machine. If your data is available on the internet, you can create a dataset out of it directly.
Upload a Dataset¶
Once you have created a dataset from the web dashboard, navigate until the directory containing your dataset from your terminal and upload the data using the floyd data commands:
floyd data init <dataset_name>floyd data upload
For example:
$ floyd data init imagenet-2017
Dataset "imagenet-2017" initialized in current directory
...
$ floyd data upload
Compressing data...
Note
Depending on the size of your dataset and the speed of your internet connection, uploading a dataset can take a while.
Here is another example where Alice is a member of the wonderland team and wants to upload the same dataset but in her team namespace:
$ floyd data init wonderland/imagenet-2017
Dataset "imagenet-2017" initialized in current directory
...
$ floyd data upload
Compressing data...
Resuming an Upload¶
Dataset uploads are resumable. If your Internet connection cuts out during an upload, you'll be able to resume it later if you choose to.
If your upload has stopped before it completing, resume it using the --resume
or -r flag:
$ floyd data upload --resume Uploading compressed data. Total upload size: 74.0MiB [= ] 4194304/77626756 - 00:00:00
If you don't pass the --resume flag, but you have an unfinished upload, you
will be prompted to specify whether or not you'd like to resume the previous
upload:
$ floyd data upload An unfinished upload exists. Would you like to resume it? [y/N]: N Compressing data...
Updating/Versioning Your Dataset¶
If you've made changes to your dataset and would like to upload it again, use the following steps. You'll notice they are the same as uploading your dataset the first time:
cdinto your dataset's directory- Run
floyd data init <dataset_name>to prepare to upload - Run
floyd data upload
Your dataset will be versioned for you, so you can still reference the old one if you'd like. Datasets will be named with sequential numbers, like this:
- alice/datasets/foo/1
- alice/datasets/foo/2
- alice/datasets/foo/3
- ...
When using a dataset in a job, be sure to reference to the dataset version that your job needs.
Understanding the Upload Process¶
When you upload a dataset to FloydHub, Floyd CLI compresses and zips your data before securely transferring it to FloydHub's servers over the Internet. Once your dataset has been uploaded, FloyHub decompresses and unzips your dataset for you. If you have a large dataset, unpacking your data on FloydHub's servers can take a while.
You can check the status of your upload using floyd data status with the name
of your dataset, as shown below:
$ floyd data status alice/datasets/mnist/1 DATA NAME CREATED STATUS DISK USAGE --------------------------- ------------- -------- ------------ alice/datasets/mnist/1 3 minutes ago valid 82.96 MB
valid is the state you're looking for. That means that your dataset has finished being unpacked and is ready to use.
Good to Know
It will not save you time to compress your dataset before uploading it, since Floyd CLI already compresses your dataset to minimize upload time.
Download large datasets directly to FloydHub from the internet¶
Often times, it might not be practical to upload datasets to FloydHub from your local machine. For example, your upload speeds might be too slow, or you just don't want to download a large dataset from the internet just to upload it again.
If your data is already available on the internet, then you can create a dataset directly on FloydHub using Workspaces. Although it is possible to create dataset from jobs, using workspace is the simpler option for downloading from the internet and tweaking it before creating a new dataset.
Step 1: Open a terminal from a running Workspace on Floydhub and download your data¶
You can create a terminal session on FloydHub within any of your running Workspaces.
Once you're in the terminal, you can download your data to your FloydHub instance.
Here is an example that downloads a CSV with details about members of the United States Congress
$ mkdir congress
$ cd congress/
$ wget https://theunitedstates.io/congress-legislators/legislators-current.csv
- Post process your data (if necessary)
For example, if the file that you downloaded is a tar file, you can untar it here. Or you can download multiple files and organize them here. Or you could open up a Jupyter notebook within this Workspace and transform your data even further.
Untar the files to the current dir $ tar xvzf train-images-idx3-ubyte.gz Remove the tar file $ rm -rf train-images-idx3-ubyte.gz
Step 2: Create a new dataset on the FloydHub Dashboard¶
Navigate to the new dataset page on Floydhub, and create your new dataset.
To continue with our Congress members example, let's call our new dataset: my-congress-members
Step 3: Use the floyd-cli to add your data to this new Dataset¶
Now, back in the terminal session of your Workspace, you can use the floyd-cli to add your current directory's files to this new dataset.
floyd data init my-congress-members floyd data upload
And you're done! If it works correctly, you should see something like this in the terminal of your Workspace:
root@floydhub:/floyd/home/congress# floyd data upload
Compressing data...
Making create request to server...
Initializing upload...
Uploading compressed data. Total upload size: 59.0KiB
[================================] 60411/60411 - 00:00:00
Removing compressed data...
Upload finished.
Waiting for server to unpack data.
You can exit at any time and come back to check the status with:
floyd data upload -r
Waiting for unpack....
NAME
----------------------------------------
alice/datasets/my-congress-members/1
Feel free to navigate over to that Dataset in your FloydHub Dashboard to explore the dataset further.
Promote job output to a dataset¶
With this feature, users will be able to save model files, data downloaded from the internet or processed dataset as a FloydHub dataset directly from a job output.
Step 1: Run a CLI Job¶
Initialized a project folder then you can launch your job:
$ floyd init alice/data-download Project "data-download" initialized in current directory $ floyd run 'wget https://theunitedstates.io/congress-legislators/legislators-current.csv' Creating project run. Total upload size: 9.2KiB Syncing code ... [================================] 12218/12218 - 00:00:01 JOB NAME ----------------------------- alice/projects/data-download/1 URL to job: https://www.floydhub.com/alice/projects/data-download/1 To view logs enter: floyd logs alice/projects/data-download/1
Step 2: Open the Job in your browser¶
Open the Job in your browser and click on the Files view.
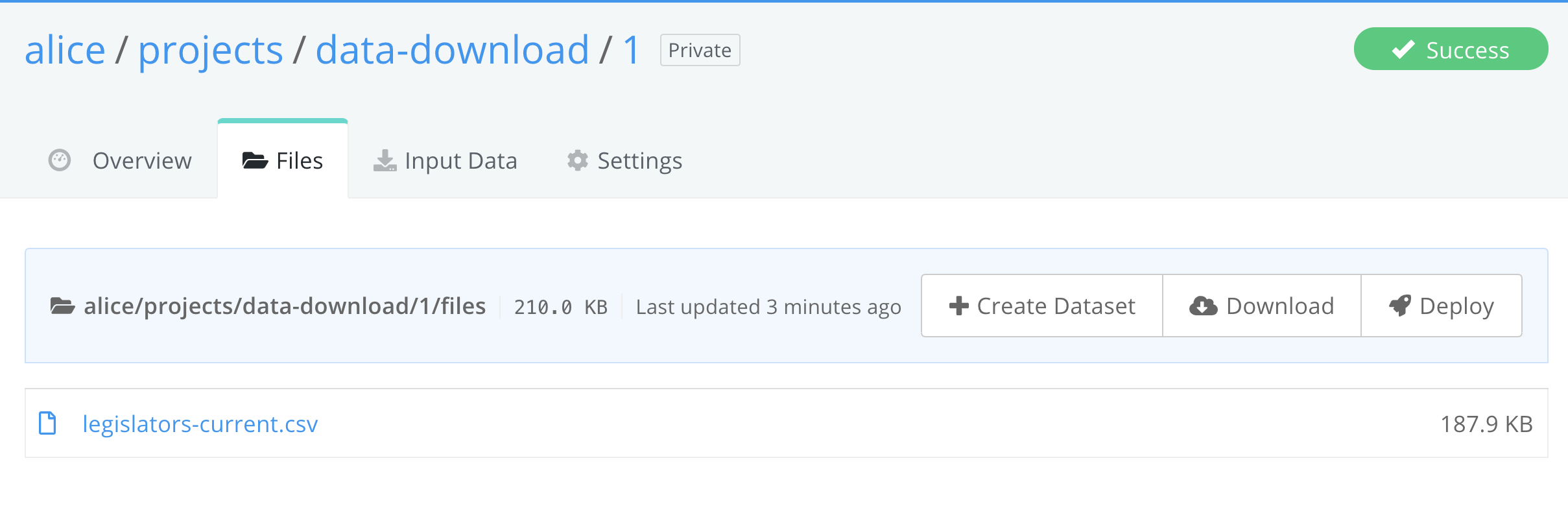
Step 3: Click the Create Dataset button¶
This will open a modal that it will ask if the job output will define a new dataset or if it will become a new dataset version.
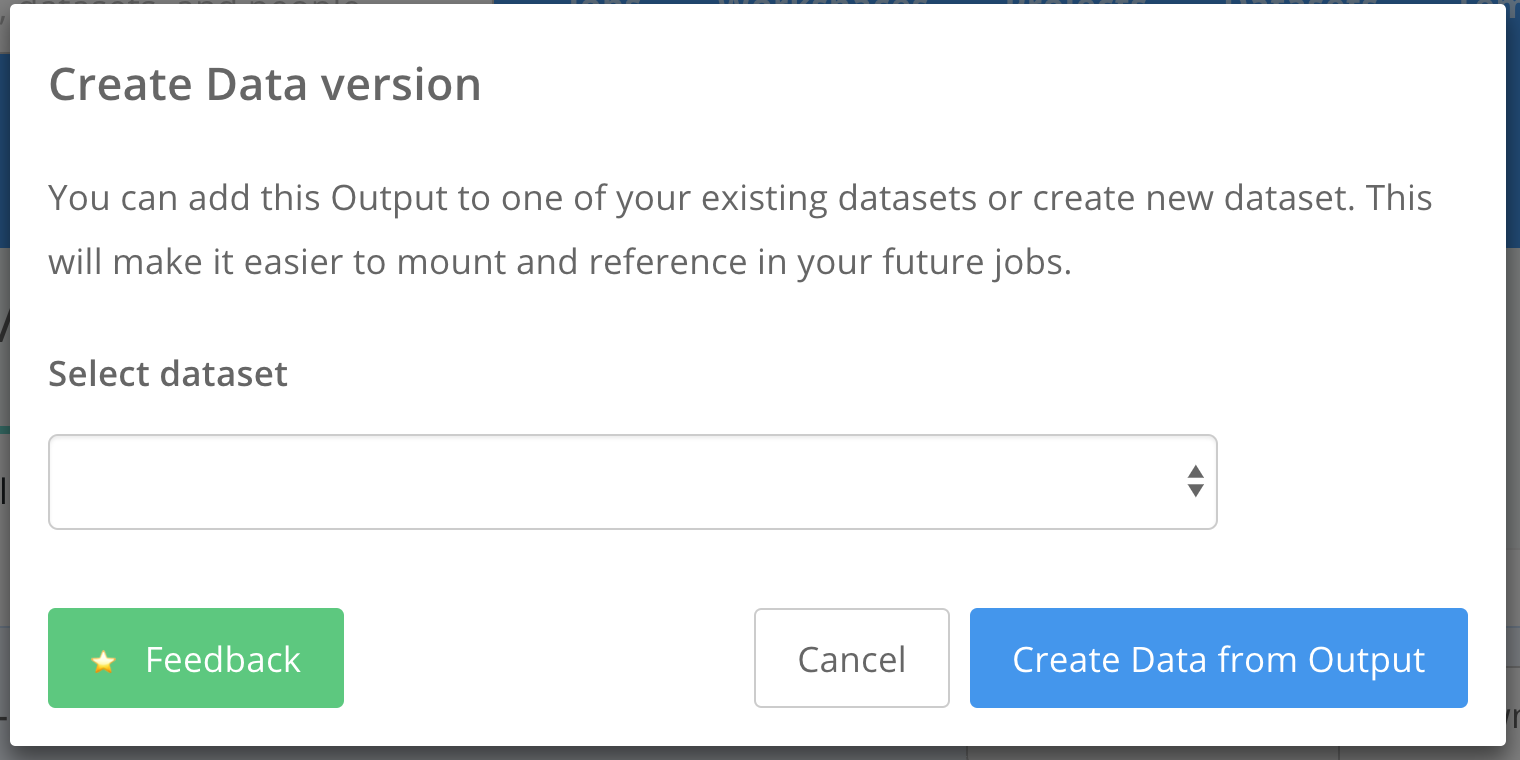
Note: You can achieve the same result with the floyd data add command.