Core Concepts¶
The essential points for understanding and effectively using FloydHub can be grouped into the following categories:
This document serves as an introduction to each of these categories. When you're ready to dive deeper, each category has its own section in our documentation that you can explore.
Projects¶
Quick Look
A project is a group of jobs and workspaces aimed at accomplishing the same goal. A project keeps track of each job, along with its output and logs. It also tracks your workspaces.
Key Points of Understanding
Billing
Learn what you will be charged for from the Billing page and FAQs
The project is the most central construct of the FloydHub platform.
Understanding what a project is on FloydHub isn't too difficult because it
directly correlates with what you'd think of as a deep learning project outside
of FloydHub: You have a problem you need to solve with a deep learning model.
You get on your computer, create a new directory with a name like mnist-cnn
and boom, you've started a new project. In that directory, you'll write some
code, run some experiments, and iterate until you have created a deep learning
model that meets your needs.
On FloydHub, a project is a collection of all the work and iterations you perform when developing a deep learning model. In contrast to a typical deep learning workflow, your experiments and training iterations (we call them jobs) will be versioned and kept organized for you to reference in the future. Workspaces provide interactive environments for you to prepare your training jobs, including pre-processing, data exploration, and other activities.
Workspaces¶
Quick Look
A workspace is an interative development environment on FloydHub for model
development, pre-processing data, and other steps in your deep learning
workflow. 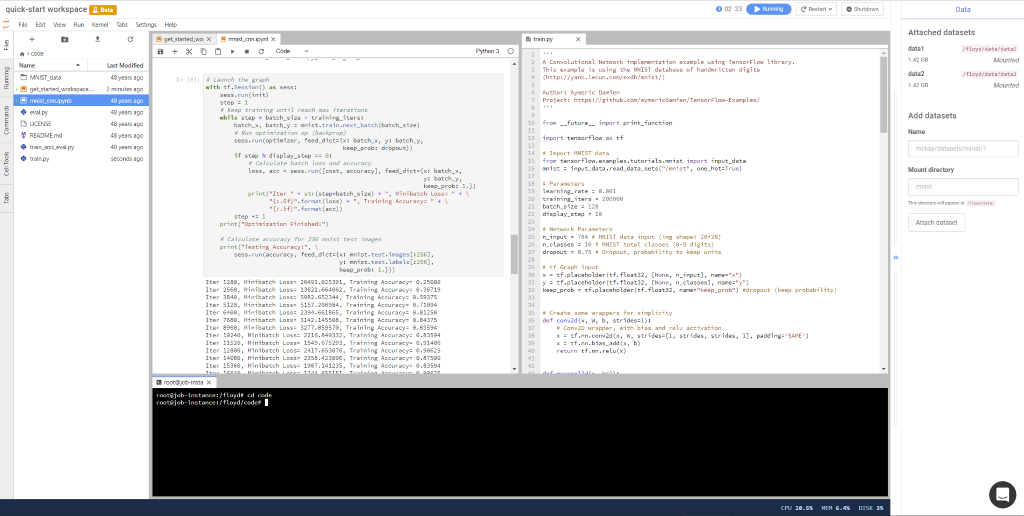
Third party cookie blocker, Ad blocker, proxy and firewall
Given the interactive web experience of Workspace, ensure that your browser accept cookies, javascript and connections from the following domains. Otherwise you may encounter a sub-par experience with Workspaces:
- floydhub.com - floydlabs.com
A workspace is a data-oriented cloud IDE (based on JupyterLab) built for deep learning and machine learning tasks. When you create a workspace, you'll select the environment and machine you'd like to use for your work. Once inside a workspace, you can easily attach FloydHub datasets, open up a terminal, or even restart your workspace with a different configuration (like switching from a CPU machine to a GPU machine)
You can create a workspace within a Project by clicking the "Create Workspace" button. You'll be able to create a blank workspace or import code from a public GitHub repository to bootstrap your workspace.
Jobs¶
Quick Look
A job is an execution of your code on FloydHub's deep-learning servers.
Key Points of Understanding
A job is what pulls together your code and dataset(s), sends them to a deep-learning server configured with the right environment, and actually kicks off the necessary code to get the data science done.
After a job is completed, you'll be able to go back and reference/review it on floydhub.com. For each job, you'll be able to see:
- A snapshot of the code used for the job
- A record of which Dataset(s) you used for the job
- A record of what Environment was used for the job
- The Output and logs of the job
You run jobs using Floyd CLI's floyd run command. The command has various
flags and parameters that let you customize how the job runs: What dataset do
you want to use? Where should the dataset be mounted on the server? What
environment do you want to use? Should the server run your job using a CPU or a
GPU? What command(s) should the server use to run your code? Any other commands
you'd like to run on the server to set it up before running your job? Etc.
Datasets¶
Quick Look
Datasets are securely uploaded to FloydHub. They are versioned and can be attached to any job.
Key Points of Understanding
FloydHub's dataset workflow is one of two things that tend to feel a bit foreign to users who are used to local development (the other being output). When working on your local machine, you might have your dataset in the same directory as your code, or in a directory where you keep many different datasets. When using FloydHub, datasets are always kept separate from code.
Why keep datasets separate from code?¶
As a data scientist you tweak your code often during the process of creating a deep-learning model. However, you don't change the underlying data nearly as often, if at all.
Each time you run a job on FloydHub, a copy of your code is uploaded to FloydHub and run on one of FloydHub's powerful deep-learning servers. Because your data isn't changing from job to job, it wouldn't make sense to keep your data with your code and upload it with each job. Instead, we upload a dataset once, and attach, or "mount", it to each job. This saves a significant amount of time on each job.
Beyond that, keeping data separate from code allows you to collaborate more easily with others. A dataset can be used by any user who has access to it, so teams and communities can work on solving problems together using the same underlying data.
Connecting code and datasets¶
You'll still be writing your code locally when using FloydHub, but when you run a job, your code will be uploaded to FloydHub and executed on a powerful deep-learning server that has your datasets mounted to it.
You can specify the places where your datasets will be mounted on the server, but you'll have to make sure that your code references your datasets with the file paths of the data on the server, not where you might have them locally.
Environments¶
Quick Look
An environment is what defines the software packages that will be available to your code during a job
Key Points of Understanding
FloydHub has a bunch of different deep learning environments to choose from. When you run a job on FloydHub, you'll be able to specify the environment you want use, straight from the command line. You'll also be able to specify whether you want the job run using a GPU or a CPU.
If FloydHub's stock deep learning environments don't meet your needs, you can create a custom environment for your job. See this guide for instructions on that.
Output¶
Quick Look
Output is any data, logs, or files from a job you want to save for future reference and use.
Key Points of Understanding
Output is anything from a job that you want to save for future use. The most common form of output is model checkpoints (the weights and biases of your model) that you developed during a job. If you save these checkpoints (or anything else you'd like to preserve) during a job, you'll have them to reference, download, and reuse in the future.
Output is the way that you can link jobs together: You run a job to test an idea you have. If it works, you may want to start where you left off and run another job. If going down that path leads to a dead end, you may want to go back to a previous output and start again from there. Knowing how to store output is key to optimizing your deep learning workflow.
Saving and reusing output on FloydHub can feel foreign to users who are used to working on their own machines. But once you learn how to do it, it becomes very simple and is one of the most valuable parts of the FloydHub workflow.