Save Output
Overview¶
Saving information generated during a job is easy.
All the files saved in the working directory (/floyd/home) will be preserved after the job or workspace finishes. In case of jobs, you will see this under the Files tab. For workspaces, you can open the workspace page to view the files.
Current Working Directory
Current Working Directory (/floyd/home/) is the only persistent directory for CLI Jobs and Workspace. It is set as the default working directory for Job and Workspace.
Anything saved in this directory at the time a job or a Workspace finishes will be preserved and can be accessed and reused later.
The most common thing users save is model checkpoints, but anything that ends up in the working directory and its subdirectories at the end of a job or a workspace session will be saved (use your imagination!).
Let's work through a couple of examples to see how to save data during a job.
Example 1¶
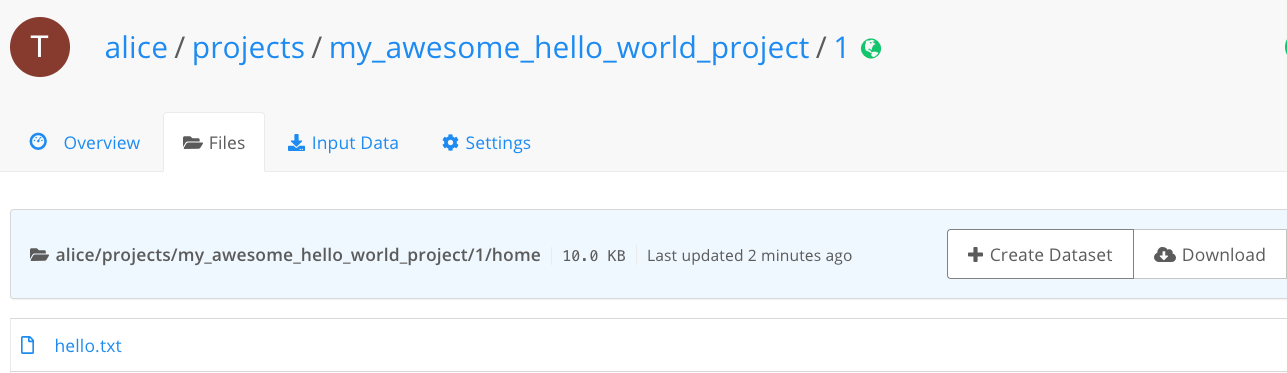
This job prints the string "Hello, world!", and saves it to a file called
hello.txt. Because hello.txt is located in the current working directory, it will
be saved and available after the job finishes:
$ floyd init my_awesome_hello_world_project $ floyd run 'echo "Hello, world!" > hello.txt' Creating project run. Total upload size: 691.0B Syncing code ...
Note
If you are not familiar with what
echo 'echo "Hello, world!" > hello.txt does, here's a quick
explanation:
- The
echo "Hello, world!"part outputs the stringHello, world!. - The
>part of the command redirects the printed output ofecho "Hello, world!"(which is, of course,Hello world!) to the file specified after the>. - The
hello.txtpart of the command specifies where theHello,world!should be written to:hello.txt. Becausehello.txtis created inside the current working directory, it will be preserved for future reference and use.
Here's the file in the Files tab:
If you want to try this in a Workspace:
- create and launch a new workspace
- open the Terminal
- run
echo "Hello, world!" > hello.txt - stop the Workspace.
Then you can view the
hello.txtfile from the workspace page:

Example 2¶
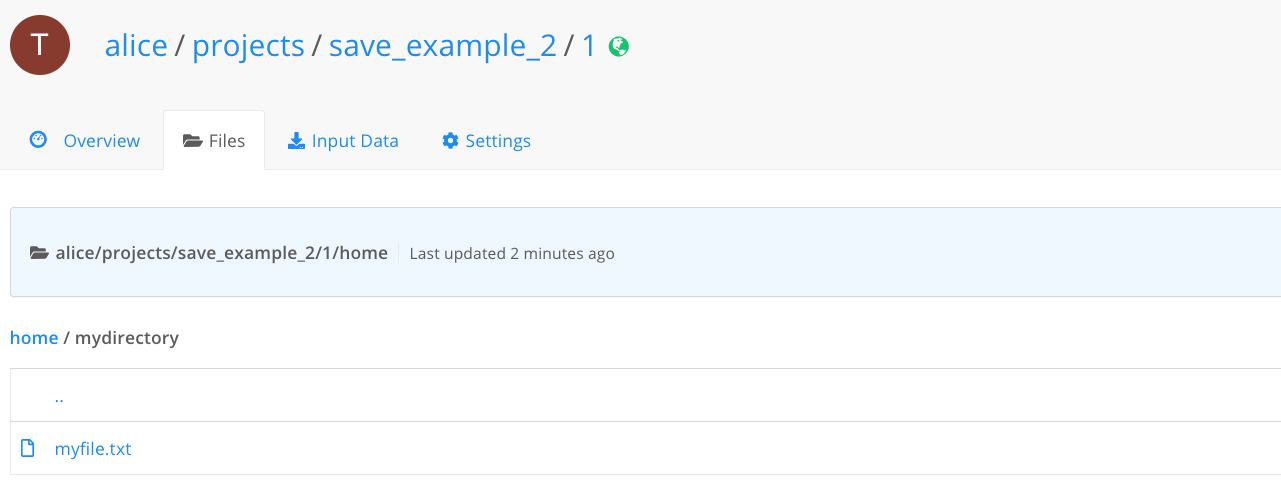
In this example, we'll use Python to save a file inside a folder in the current working directory
directory. Put this code in a file named save_example.py:
import os # Create the directory if not exists if not os.path.exists('mydirectory'): os.makedirs('mydirectory') # Create the file inside the directory with open('mydirectory/myfile.txt', 'a') as f: f.write('Please save me!\n')
Then run the execution on FloydHub:
$ floyd init save_example_2 $ floyd run "python save_example.py" Creating project run. Total upload size: 267.0B Syncing code ...
Now that we've completed a couple trivial examples, let's do something more useful and realistic.
Example 3¶
Here is a sample Tensorflow example that saves a model checkpoint. Because we
write (save) the data to the models directory (a folder inside the current working directory), we'll be able to use it later. A future job can use this model checkpoint as a starting point.
Consider this partial code, and note the call to saver.save(sess,'models/model.ckpt'):
import tensorflow as tf ... saver = tf.train.Saver() with tf.Session() as sess: sess.run(init) ... save_path = saver.save(sess, 'models/model.ckpt') print("Model saved in file: %s" % save_path) ...
Because model is stored in a folder inside the current working directory, it will be saved even after your job or workspace session ends, and can be used again in future jobs or when the workspace is restarted.
Using Files as a data source¶
You can use the Files of one job as the input to your next job. To see how to mount Files data, please see this guide
Help make this document better¶
This guide, as well as the rest of our docs, are open-source and available on GitHub. We welcome your contributions.
- Suggest an edit to this page (by clicking the edit icon at the top next to the title).
- Open an issue about this page to report a problem.