Metrics
FloydHub provides various metrics for your training jobs in order to help you measure how well your job's training process is going. These metrics are visible as graphs on the job overview page.
Metrics are collected once every 60 seconds and will be updated in real time during a job's training process. Metrics will be retained after the job is completed - however, we are still determining the default retention period.
Metrics are grouped into two categories:
- System Metrics: System stats, such as CPU or GPU utilization
- Training Metrics: Custom training metrics, like training accuracy, loss, etc.
System Metrics¶
System metrics provide insight into the system stats of your FloydHub training machine. These metrics will be automatically collected for all types of jobs - Command Mode and Serving Mode.

For all jobs, you will receive:
- CPU Utilization: Percentage of CPU usage by your training job
- Memory Utilization: Percentage of RAM usage by your training job
- Disk Utilization: Percentage of SSD usage by your training job
Additionally, for any GPU-powered jobs, you will receive:
- GPU Utilization: Percentage of GPU usage by your training job
- GPU Memory Utilization: Percentage GPU Memory by your training job
These metrics provide insight to help you optimize your training jobs. For example, the GPU Memory Utilization metric might indicate that you should increase or decrease your batch size to ensure that you're fully utilizing your GPU. It can also help you debug failed jobs due to out-of-memory (OOM) errors.
Training Metrics¶
Training metrics come from the logs of the Python training script used by your job. FloydHub parses your job's output lines (anything printed to stdout) and automatically converts them into Training Metrics.
Important
Training metrics are currently only available for Command Mode jobs - not Serving jobs.
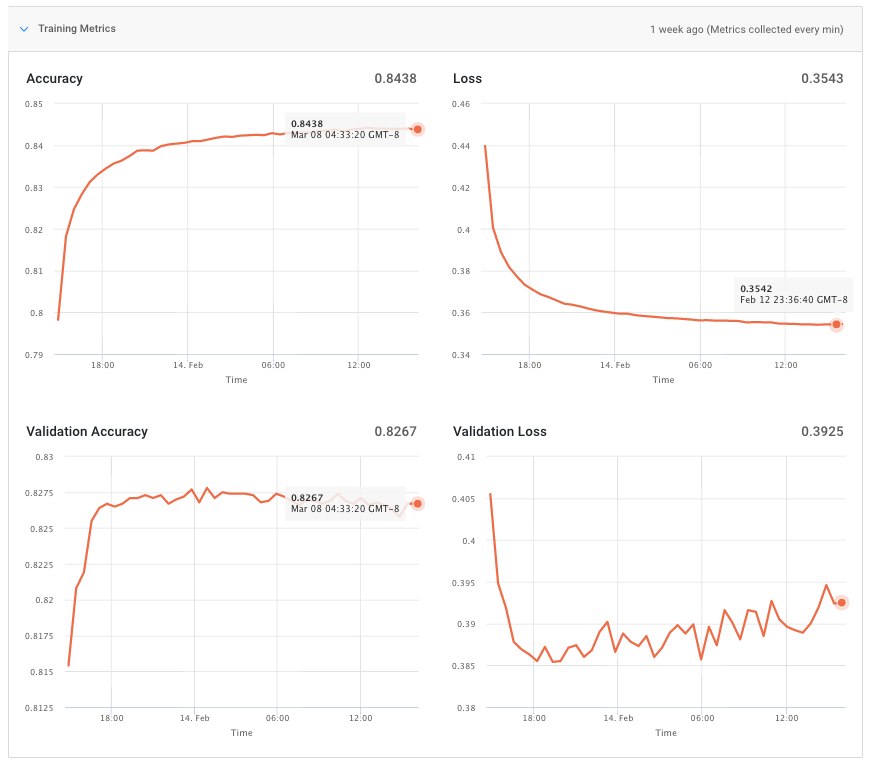
Currently, our system can identify and parse the default Keras logs and FloydHub will automatically convert them to Training Metrics. Here's an example of a Keras log line:
700000/700000 [==============================] - 20s - loss: 0.4097 - acc: 0.8078 - val_loss: 0.4582 - val_acc: 0.781
If you are using a different framework, such as PyTorch, you can still send your own training metrics data to stdout. FloydHub will not parse them automatically, but if you send them in JSON format with one metric per line, then we will be able to display them as Training Metrics.
Here is the basic format:
print('{"metric": "<choose_metric_name>", "value": <int_or_float>}')
For example, if you want to report accuracy values:
print('{"metric": "accuracy", "value": 0.985}') # {"metric": "accuracy", "value": 0.985}
print('{{"metric": "loss", "value": {}}}'.format(loss)) # {"metric": "loss", "value": 1.000000}
You can send any metric you want as a Training Metric, however the only values we accept currently are float or integer values. If you are interested in sending other values as custom training metrics, please let us know by sending an email to support@floydhub.com.
Steps¶
By default, Training Metrics will show Time as the x-axis. However, you can also toggle the Training Metrics to display steps, as long as you provide that information in your logs.
Here is the basic format. Notice that you'll need to provide an integer value for the step field:
print('{"metric": "<metric_name>", "value": <int_or_float>, "step": <int>}')
And here is an example:
print('{"metric": "accuracy", "value": 0.985, "step": 3}') # {"metric": "accuracy", "value": 0.985. "step": 3}
We will also display epoch as a Step if you emit this value as an integer. Here's the format:
print('{"metric": "<metric_name>", "value": <int_or_float>, "epoch": <int>}')
And here's an example with epoch:
print('{"metric": "accuracy", "value": 0.985, "epoch": 5}') # {"metric": "accuracy", "value": 0.985. "epoch": 5}
We'll automatically identify and parse the "Epoch" for Keras logs -- your Keras job will use this value as the "Step" value in its Training Metrics charts.
How to integrate Training Metrics in your code¶
Here are some useful resources for helping you add Training Metrics to your project.
TensorFlow¶
One of our power user, David Mack, created a really useful tf.hook that you can use with the tf.EstimatorSpec API, here's the gist of the code:
import tensorflow as tf import numpy as np class FloydHubMetricHook(tf.train.SessionRunHook): """An easy way to output your metric_ops to FloydHub's training metric graphs This is designed to fit into TensorFlow's EstimatorSpec. Assuming you've already defined some metric_ops for monitoring your training/evaluation, this helper class will compute those operations then print them out in the format that FloydHub is expecting. For example: ``` def model_fn(features, labels, mode, params): # Set up your model loss = ... my_predictions = ... eval_metric_ops = { "accuracy": tf.metrics.accuracy(labels=labels, predictions=my_predictions) "loss": tf.metrics.mean(loss) } return EstimatorSpec(mode, eval_metric_ops = eval_metric_ops, # **Here it is! The magic!! ** eval_hooks = [FloydHubMetricHook(eval_metric_ops)] ) ``` FloydHubMetricHook has one optional parameter, *prefix* for using it multiple times (e.g. prefix="train_" for training metrics, prefix="eval_" for evaluation metrics). """ def __init__(self, metric_ops, prefix=""): self.metric_ops = metric_ops self.prefix = prefix self.readings = {} def before_run(self, run_context): return tf.train.SessionRunArgs(self.metric_ops) def after_run(self, run_context, run_values): if run_values.results is not None: for k,v in run_values.results.items(): try: self.readings[k].append(v[1]) except KeyError: self.readings[k] = [v[1]] def end(self, session): for k, v in self.readings.items(): a = np.average(v) # You can add the step attribute by using tf.train.get_global_step() API print(f'{{"metric": "{self.prefix}{k}", "value": {a}}}') self.readings = {}
Keras¶
Keras offers a lot of flexibility with the Callbacks API. Here's a callback that you can use for integrating Training Metrics:
import keras from sklearn.metrics import f1_score class FloydhubTrainigMetricsCallback(keras.callbacks.Callback): """FloydHub Training Metric Integration""" def on_epoch_end(self, epoch, logs=None): """Print Training Metrics""" print('{{"metric": "F1Score", "value": {}, "epoch": {}}}'.format(logs.get('F1Score'), epoch)) # or you can compute it on the fly ... score = f1_score(target, prediction) print('{{"metric": "F1Score_onfly", "value": {}, "epoch": {}}}'.format(score, epoch)) model.fit(..., epochs=10, verbose=2, callbacks=[FloydhubTrainigMetricsCallback()], ...)
PyTorch¶
Unlike TensorFlow and Keras, PyTorch does not provide any callbacks or training hooks for this use-case. But you can easily integrate Training Metrics in your code with a function at the end of your epoch or batch loop.
import torch.nn.functional as F def floyd_training_metrics(classifier, epoch=10, test_batch_size=32): """FloydHub Training Metric integration""" test_loader = get_test_loader(test_batch_size, train=False) classifier_test_loss = 0 for test_data, test_target in test_loader: test_data, test_target = test_data.to(device), test_target.to(device) prediction = classifier(test_data) classifier_loss += F.nll_loss(prediction, test_target).data.numpy() print('{{"metric": "NLL Loss", "value": {}, "epoch": {}}}'.format( classifier_loss.item(), epoch)) def train(classifier, optimizer, train_loader, epochs=10): """E.g. of a training function in PyTorch 1.0""" ... for epoch in range(epochs): classifier.train() for data, target in train_loader: data, target = data.to(device), target.to(device) optimizer.zero_grad() prediction = classifier(data) classifier_loss = F.nll_loss(prediction, target) classifier_loss.backward() optimizer.step() ... # Return Training Metrics at the end of each epochs floyd_training_metrics(classifier, epoch, test_batch_size) ...